[책 읽고 정리] 파이썬으로 살펴보는 아키텍처 패턴 (Part1)
![[책 읽고 정리] 파이썬으로 살펴보는 아키텍처 패턴 (Part1)](/images/posts/architecture_patters_with_python_part1.jpg)
작은 서비스를 만들 때는 일단 잘 돌아가게 하는 것이 중요하다고 생각했다. (일단 대충 돌아가게 하는 것과는 다르다)
그래야 나와 함께 손발을 맞추는 동료들이 너무 오래 기다리지 않고, 다양한 시도를 해볼 수 있으니 말이다.
그렇게 서비스가 커지고 사용자도 늘어나면서 나중을 상상해보곤 한다.
‘이 설계가 그때는 맞았지만 나중에도 맞을까?’, ‘갑자기 많은 사용자가 들어오면 괜찮을까?’
물론 아무런 준비도 안 되어 있는 건 아니지만, 가끔 드는 불안감은 어쩔 수 없는 것 같다.
그럴 때는 뭐라도 하는 게 맞으니까…
이 책을 읽어봐야겠다고 생각한 계기는 어떤 카카오톡 오픈 채팅에서 느꼈던 분위기 때문이다.
DDD에 대한 이야기가 오고 가는데 알아들을 수 있는 말이 많지 않았다.
예전에 사내에서 DDD 스터디를 정주행했던 적은 있지만, 깊이가 얕고 실천 계획이 동반되지 않아서 금방 잊혀졌다.
아무튼 그때 나랑 비슷한 느낌을 받았을 것 같은 누군가의 질문에 이 책을 권했던 사람이 있었다.
그날 바로 서점에 가서 샀는데 예상보다 얇아서 기뻤다(?)
2주 정도 출퇴근하는 지하철 안에서 읽었는데 겨우 Part1까지 읽고, (너무 기억 나는 게 없어서) 주말에 다시 복습하며 이 정리를 작성했다.
얇아서 출퇴근할 때 읽기 좋겠다고 생각했던 건 큰 오산이었다.
절대 한 번에 이해할 수 있는 내용이 아니고, 아직 TDD, DDD에 대한 기본적인 이해가 없다면 절대 먼저 보면 안 된다.
나는 우선 Part1까지만 읽고, 다른 DDD 관련 책이나 인터넷 자료 조사를 통해 감을 더 끌어 올릴 계획이다.
어쨌든 책은 정말 좋다. 특히 파이썬을 좋아하는 사람으로서 이 책의 예제 코드를 읽고, 이해하는 과정이 즐거웠다.
Part1 - 도메인 모델링을 지원하는 아키텍처 구축
Chapter 1 - 도메인 모델링
- 도메인 모델의 핵심 패턴은 엔티티(Entity), 값 객체(Value Object), 도메인 서비스(Domain Service)
- 도메인이란? 해결하려는 문제일 뿐
- 모델은? 유용한 특성을 포함하는 프로세스나 현상의 지도
- 도메인 모델은? 비즈니스를 수행하는 사람이 자신의 비즈니스에 대해 가지고 있는 지도와 같다.
- 값 객체 (Value Object)
- 데이터는 있지만 유일한 식별자가 없는 비즈니스 개념을 표현하기 위해 값 객체(Value Object)를 사용한다.
- 값 객체는 안에 있는 데이터에 따라 유일하게 식별될 수 있는 도메인 객체를 의미하며, 불변 객체(Immutable Object)로 만들곤 한다.
- Python에서 불변 객체를 만들기 위해 데이터 클래스나 네임드 튜플을 이용해서 값 동등성(value equality)를 부여할 수 있다.
- 책 예제 인용: 주문(Order)에는 그 주문을 식별할 수 있는 유일한 참조 번호(예: 주문 ID)가 있지만 라인(OrderLine)은 그렇지 않다. 주문 라인은 그 라인의 주문 ID, SKU, 수량을 변경하면 새로운 라인이 된다. 즉, 데이터에 의해 결정되며 오랫동안 유지되는 정체성이 존재하지 않는다.
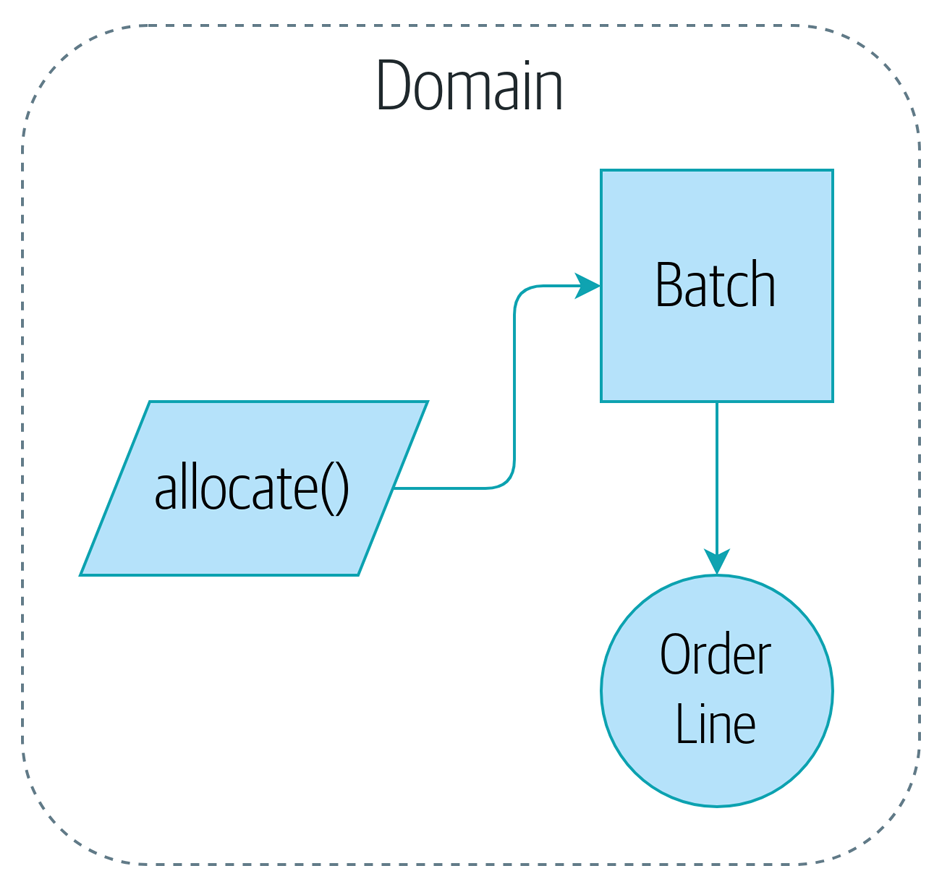
- 엔티티(Entity)
- 오랫동안 유지되는 정체성이 존재하는 도메인 객체를 설명할 때 사용한다.
- 이름을
Name이라는 클래스로 정의한다면 이름이 다른Name객체는 서로 같지 않다. 하지만Name객체를 갖는 사람(Person) 클래스는 영속적인 정체성(persistent identity)을 갖고 있다. - 따라서 값 객체와 달리 엔티티에는 정체성 동등성(identity equality)이 있다.
- 모든 것을 객체로 만들 필요가 없다.
- 코드에서 ‘동사(verb)‘에 해당하는 부분을 표현하려면 함수를 사용하는 것이 좋다.
FooManager,BarBuilder,BazFactory대신manage_foo(),build_bar(),get_baz()함수를 쓰는 편이 가독성이 더 좋고 표현력이 좋다.
Chapter 2 - 저장소 패턴 (Repository)
- 데이터 저장소를 간단하게 추상화한 것으로 이 패턴을 사용하면 모델 계층과 데이터 계층을 분리할 수 있다.
- 이 간단한 추상화는 데이터베이스의 복잡성을 감춰서 시스템을 테스트하기 더 좋게 만든다.
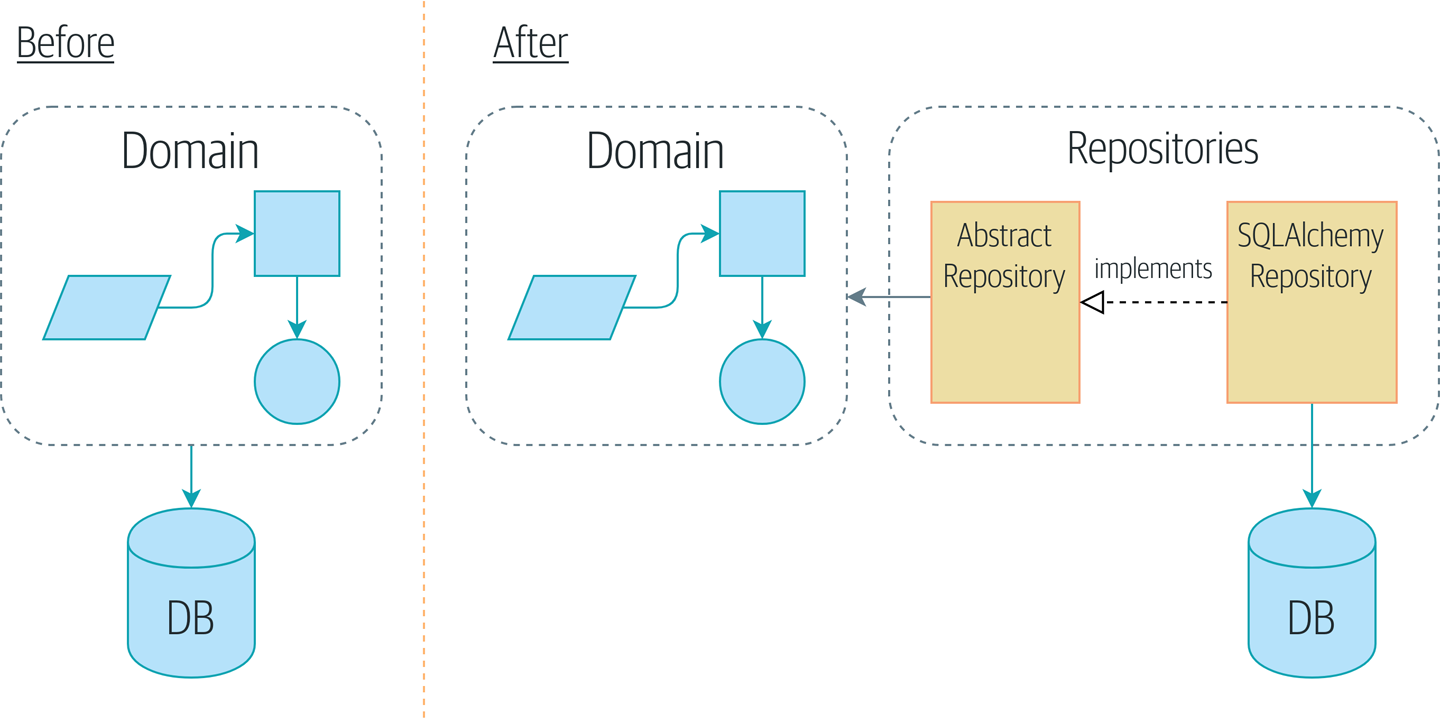
- 도메인 모델에는 그 어떤 의존성도 없어야 한다.
- 하부 구조와 관련된 문제가 도메인 모델에 지속적으로 영향을 끼쳐서 단위 테스트를 느리게 하고 도메인 모델을 변경할 능력이 감소된다.
- 모델을 내부에 있는 것으로 간주하고, 의존성이 내부로 들어오도록 만들어야 한다.
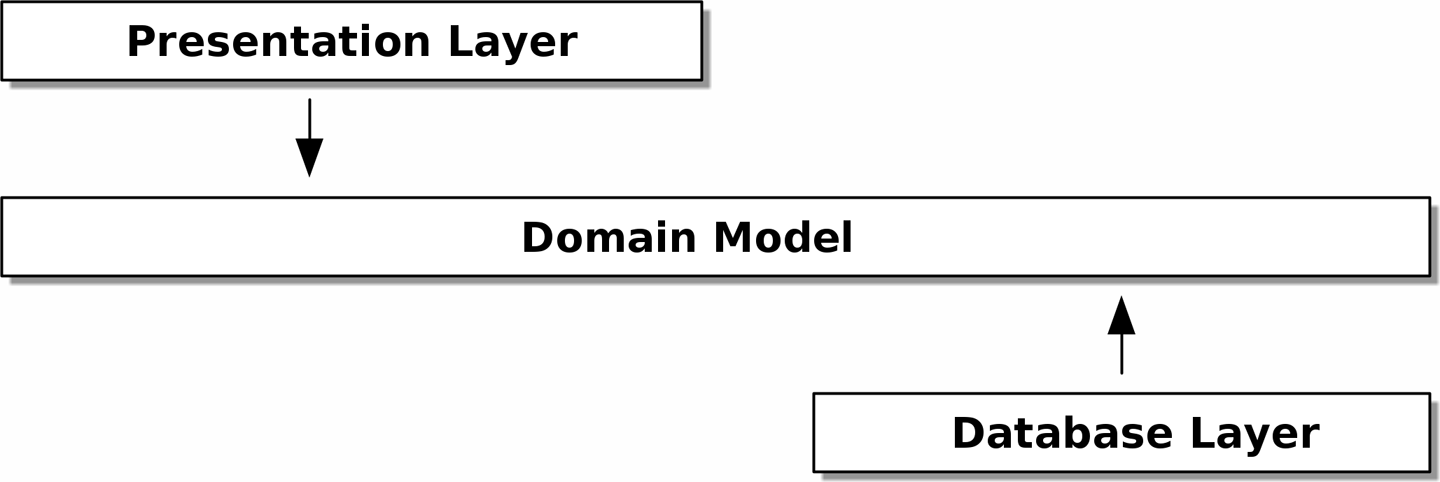
이 모델을 관계형 데이터베이스로 연결하려면 어떻게 해야할까?
- 일반적인 ORM(객체 관계 매핑) 방식: ORM에 의존하는 방식
- ORM이 제공하는 가장 중요한 기능은 영속성 무지(persistent ignorance)다. 도메인 모델이 데이터를 어떻게 저장하는 지에 대해 알 필요가 없다는 의미다.
- 영속성 무지가 성립하면 특정 데이터베이스 기술에 도메인이 직접 의존하지 않도록 유지할 수 있다.
- 이 관점에서 ORM을 사용하는 것은 이미 DIP(의존성 역전)의 한 예다. 하드코딩한 SQL에 의존하는 대신 추상화인 ORM을 의존한다. 하지만 이것만으로 충분하지 않다.
이 모델이 데이터베이스에 대해 무지하다고 말할 수 있을까? 모델 프로퍼티가 직접 데이터베이스 열과 연관되어 있는데 어떻게 저장소와 관련된 관심사를 모델로부터 분리할 수 있을까?
from sqlalchemy import Column, ForeignKey, Integer, String from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship Base = declarative_base() class Order(Base): id = Column(Integer, primary_key=True) class OrderLine(Base): id = Column(Integer, primary_key=True) sku = Column(String(250)) qty = Integer(String(250)) order_id = Column(Integer, ForeignKey('order.id')) order = relationship(Order)- 의존성 역전 : 모델에 의존하는 ORM
- 스키마를 별도로 정의하고 스키마와 도메인 모델을 상호 변환하는 매퍼(mapper)를 정의한다.
start_mapper()함수를 호출하지 않으면 도메인 모델 클래스는 데이터베이스를 인식하지 못한다.from sqlalchemy.orm import mapper, relationship import model #(1) metadata = MetaData() order_lines = Table( #(2) "order_lines", metadata, Column("id", Integer, primary_key=True, autoincrement=True), Column("sku", String(255)), Column("qty", Integer, nullable=False), Column("orderid", String(255)), ) ... def start_mappers(): lines_mapper = mapper(model.OrderLine, order_lines)저장소 패턴 소개
- 저장소 패턴은 영속적 저장소를 추상화한 것이다. 모든 데이터가 메모리상에 존재하는 것처럼 데이터 접근과 관련된 세부 사항을 감춘다.
- 가장 간단한 저장소에는
add(),get()메서드 두 가지 밖에 없다. 이렇게 단순성을 강제로 유지하면 도메인 모델과 데이터베이스 사이의 결합을 끊을 수 있다. - 저장소 패턴과 ORM은 모두 Raw SQL문을 대신하는 추상화 역할을 한다. 저장소 뒤에 ORM을 쓰거나 ORM 뒤에 저장소를 쓸 필요가 없다. ORM 없이 직접 저장소를 구현하지 이유는 없다.
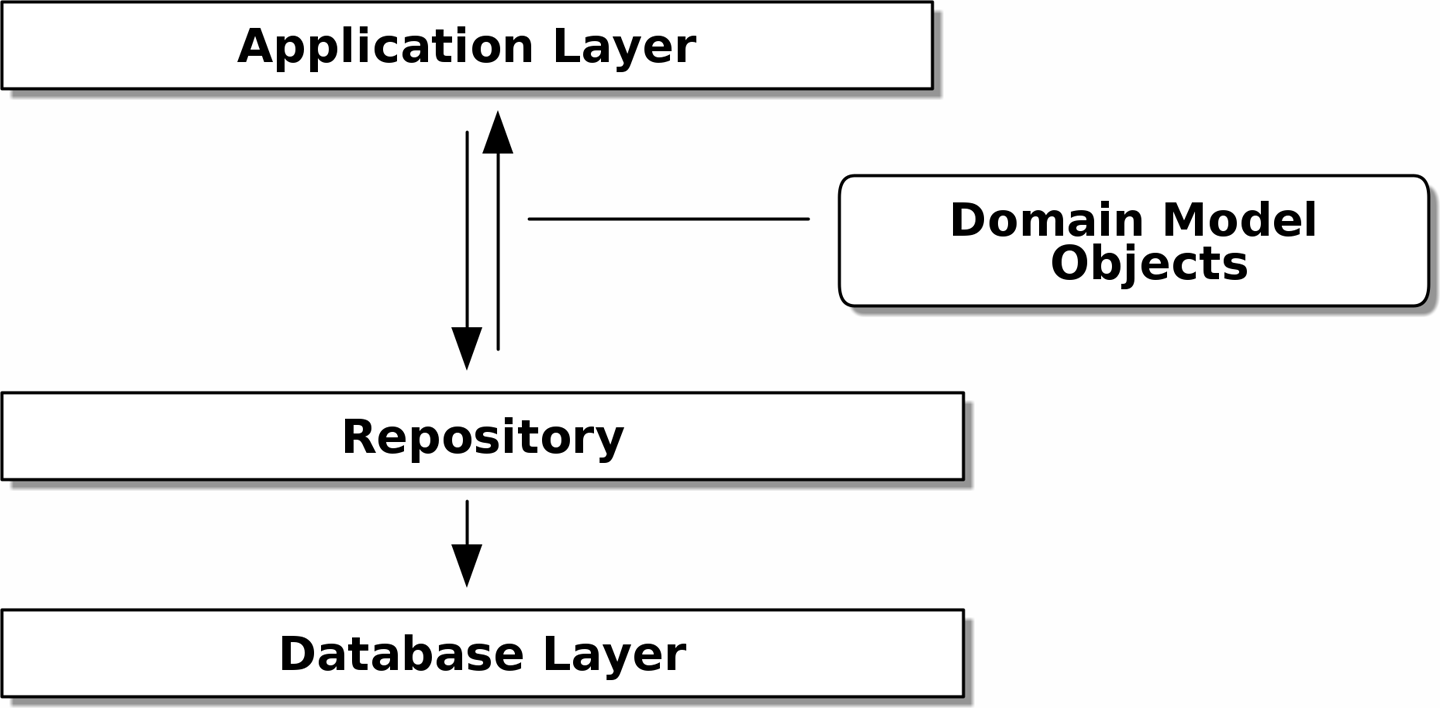
- 정리하자면, 도메인 모델은 인프라에 대해 걱정할 필요가 없어야 한다. ORM은 모델을 임포트해야 하며 모델이 ORM을 임포트해서는 안된다.
- 저장소 패턴은 영속적 저장소에 대한 단순한 추상화다. 저장소는 컬렉션이 메모리상에 있는 객체라는 환상을 제공한다. 저장소를 사용하면 핵심 애플리케이션에는 영향을 미치 앟으면서 인프라를 이루는 세부 구조를 변경하거나
FakeRepository를 쉽게 작성할 수 있다.
Chapter 3 - 결합과 추상화
- 저장소 패턴은 영구 저장소에 대한 추상화다.
- B 컴포넌트가 깨지는 게 두려워서 A 컴포넌트를 변경할 수 없는 경우 이 두 컴포넌트가 서로 결합되어 있다고 한다.
- 지역적 결합은 좋은 것이다. 결합된 요소들 사이에 응집(cohesion)이 있다는 용어로 표현한다. 하지만 전역적 결합은 성가신 존재다. 코드를 변경하는 데 드는 비용을 증가시킨다.
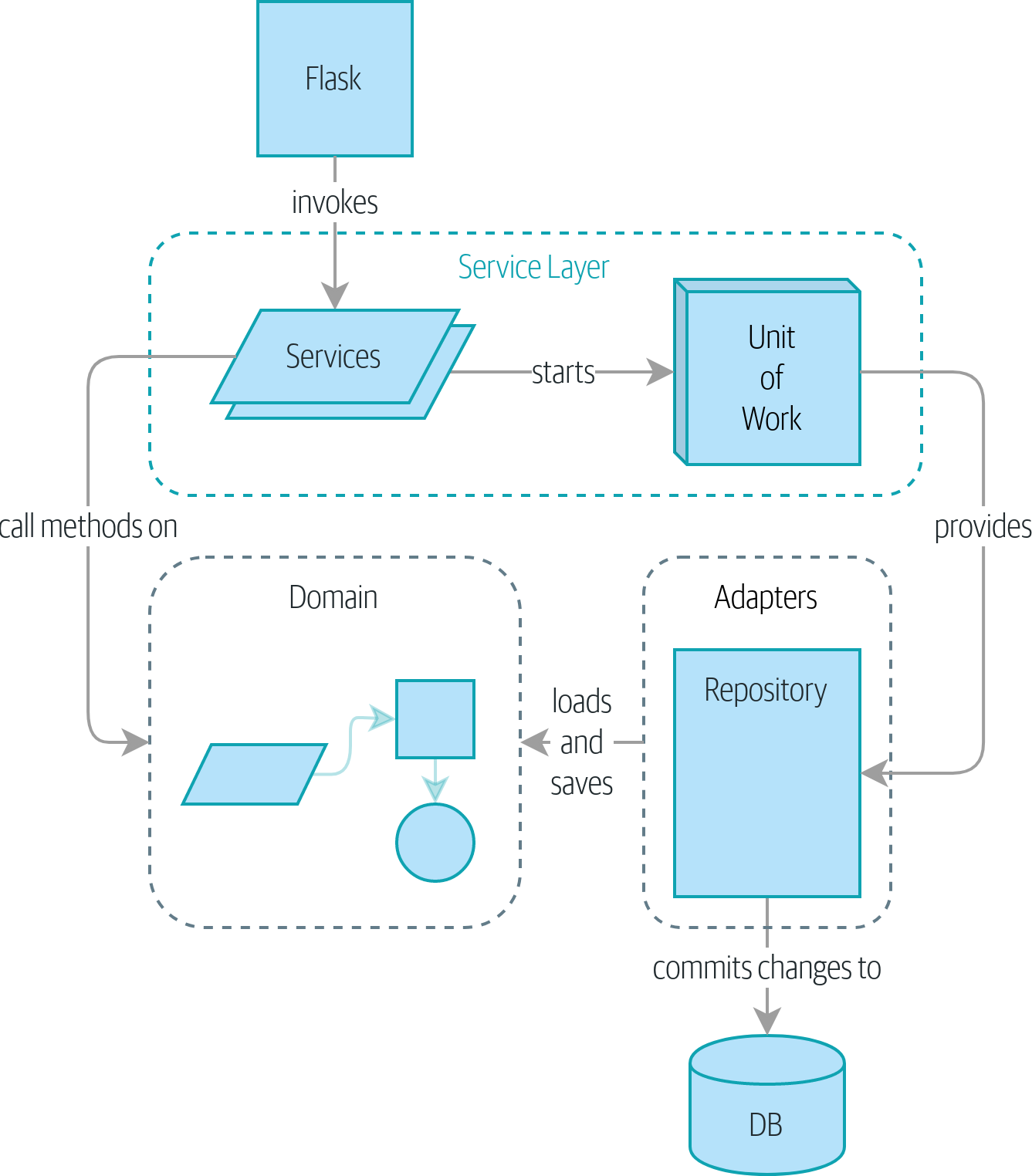
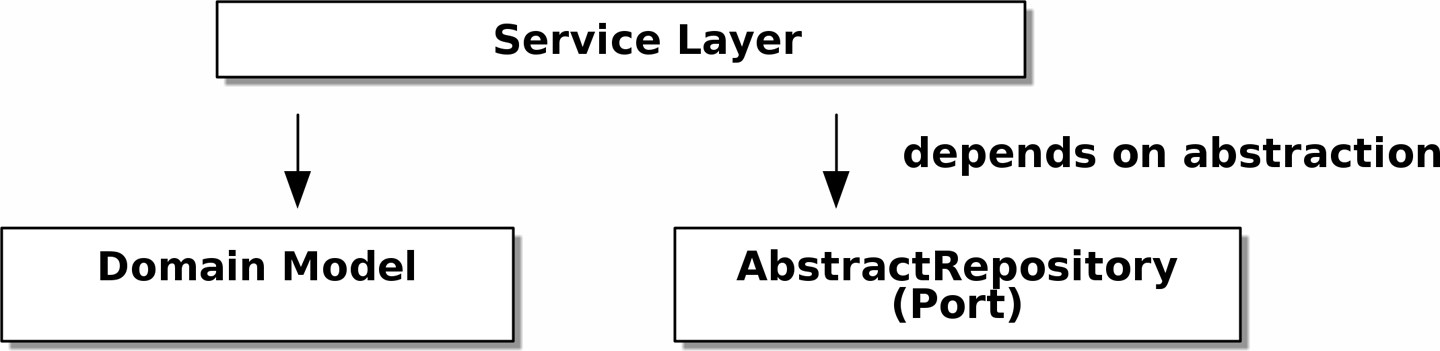
Chapter 4 - 플라스크 API와 서비스 계층
- 서비스 계층은 플라스크와 도메인 모델 사이에 유스 케이스를 담는 추상화 역할을 할 수 있게 한다.
- 실제 API 엔드포인트(HTTP)와 실제 데이터베이스를 사용하는 테스트를 E2E(end to end) 테스트라고 부른다.
아래 코드는 플라스크 함수에서 몇 가지 오류 처리를 추가하고 있다. 이렇게 할수록 점점 E2E 테스트 개수가 늘어나서 역 피라미드형 테스트가 된다.
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"],
)
if not is_valid_sku(line.sku, batches):
return {"message": f"Invalid sku {line.sku}"}, 400
try:
batchref = model.allocate(line, batches)
except model.OutOfStock as e:
return {"message": str(e)}, 400
session.commit()
return {"batchref": batchref}, 201
- 플라스크 앱이 하는 일을 살펴보면 오케스트레이션이라고 부르는 요소가 상당 부분을 차지한다.
- 저장소에서 여러 가지 가져오고, 데이터베이스 상태에 따라 입력을 검증하고 오류를 처리하며, 성공적인 경우 데이터를 커밋한다. 이런 작업 대부분은 웹 API 엔드포인트와 관련이 없다.
- 오케스트레이션은 E2E 테스트에서 실제로 테스트해야 하는 대상이 아니다.
- 서비스 2가지 요소로 불린다. 첫번째 애플리케이션 서비스는 다음과 같은 간단한 단계를 수행하여 애플리케이션을 제어한다.
- 데이터베이스에서 데이터를 얻는다.
- 도메인 모델을 업데이트한다.
- 변경된 내용을 영속화한다.
- 두 번째 도메인 서비스는 도메인 모델에 속하지만 근본적으로 상태가 있는 엔티티나 값 객체에 속하지 않는 로직을 부르는 이름이다.
Chapter 5 - 높은 기어비와 낮은 기어비의 TDD
- 서비스 계층에 대해 테스트하면 더는 도메인 모델 테스트가 필요없다.
# domain-layer test:
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
# service-layer test:
def test_prefers_warehouse_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
repo = FakeRepository([in_stock_batch, shipment_batch])
session = FakeSession()
line = OrderLine('oref', "RETRO-CLOCK", 10)
services.allocate(line, repo, session)
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
- 테스트가 있으면 시스템을 바꾸는데 두려움이 없다. 하지만 도메인 모델에 대한 테스트가 너무 많으면 코드 베이스를 바꿀 때마다 많은 테스트를 변경해야 하는 문제가 생긴다.
- 변하면 안 되는 시스템의 특성을 강제로 유지하기 위해 테스트를 사용한다. 예를 들어 API가 계속 200OK를 반환하는지, 데이터베이스 세션이 커밋을 하는지, 주문이 여전히 할당되는지…
- API에 대한 테스트를 작성하면 도메인 모델을 리팩터링할 때 변경해야 하는 코드의 양을 줄일 수 있다.
- 서비스 계층에 대한 테스트만 수행하도록 우리 자신을 제한하자.
- 직접 모델 객체의 ‘사적인’ 속성이나 메서드와 테스트가 직접 상호작용하지 못하게 막는다면 좀 더 자유롭게 모델을 리팩터링할 수 있다.
- 온전히 서비스 계층의 기능만 사용하는 서비스 계층 테스트를 작성하면 도메인에 대한 의존 관계를 모두 제거할 수 있다.
- 일반적으로 서비스 계층 테스트에서 도메인 계층에 있는 요소가 필요하다면 이는 서비스 계층이 완전하지 않다는 의미
# tests/unit/test_services.py
def test_add_batch():
repo, session = FakeRepository([]), FakeSession()
services.add_batch("b1", "CRUNCHY-ARMCHAIR", 100, None, repo, session)
assert repo.get("b1") is not None
assert session.committed
# service_layer/services.py
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
repo: AbstractRepository, session,
) -> None:
repo.add(model.Batch(ref, sku, qty, eta))
session.commit()
def allocate(
orderid: str, sku: str, qty: int,
repo: AbstractRepository, session
) -> str:
- 서비스 계층을 도메인 객체가 아니라 원시 타입을 바탕으로 작성하라
# 이전: allocate는 도메인 객체를 받는다 (service_layer/services.py)
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:
pass
# 이후: allocate는 문자열과 정수를 받는다
def allocate(
orderid: str, sku: str, qty: int,
repo: AbstractRepository, session
) -> str:
pass
- 이상적인 경우 테스트해야 할 모든 서비스를 오직 서비스 계층을 기반으로 테스트할 수 있다.
Chapter 6 - 작업 단위 패턴 (UoW)
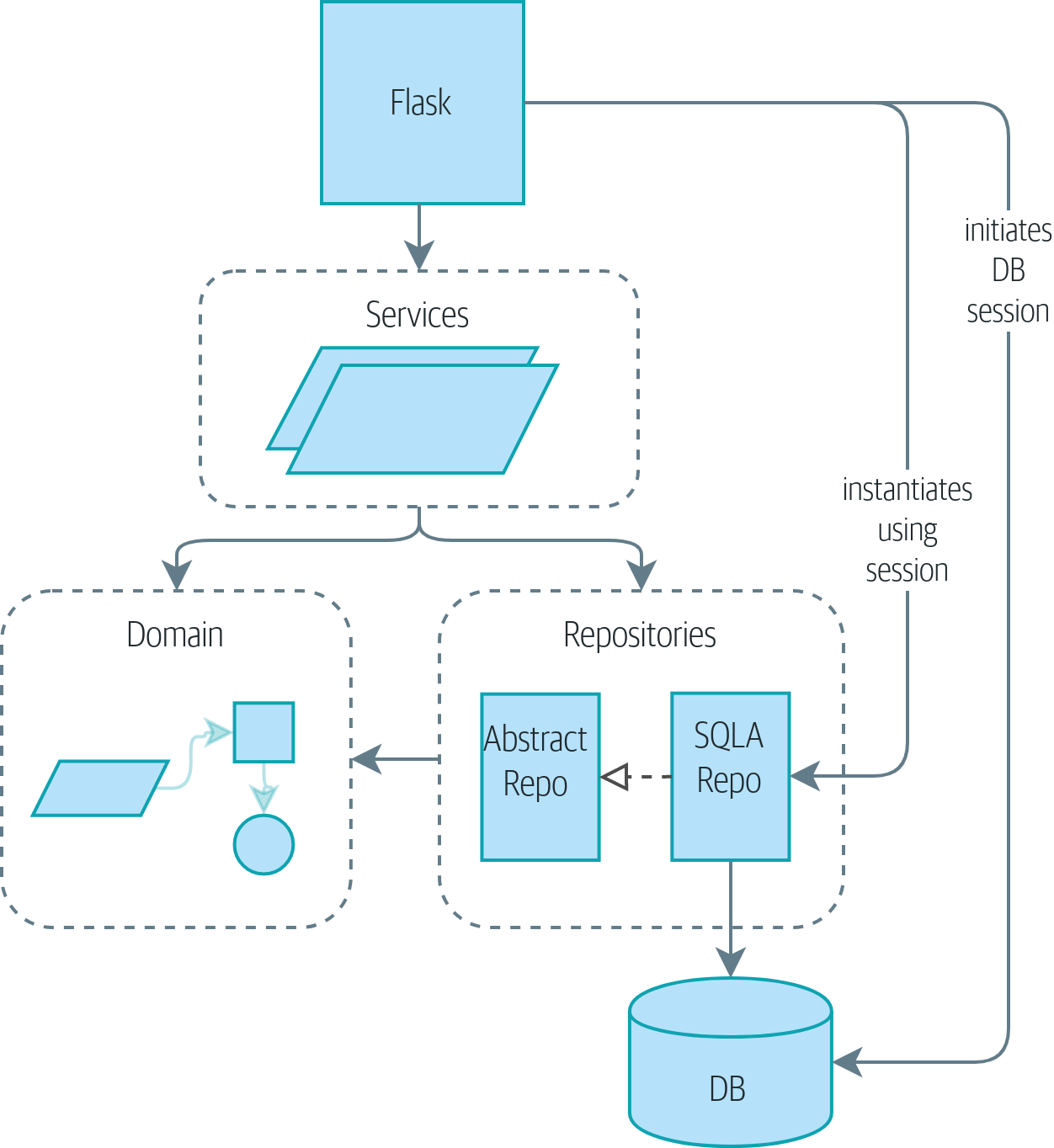
- 저장소와 서비스 계층 패턴을 하나로 묶어 주는 마지막 퍼즐은 Unit of Work(UoW) 패턴이다.
- 저장소 패턴이 영속적 저장소 개념에 대한 추상화라면 UoW는 원자적 연산(Atomic operation) 개념의 추상화다.
- UoW 패턴을 사용하면 서비스 계층과 데이터 계층을 완전히 분리할 수 있다.
▼ UoW가 없는 경우: API는 서비스 계층, 저장소 계층, 데이터베이스와 직접 소통한다.
▼ UoW가 있는 경우 : UoW가 데이터베이스 상태를 관리한다.
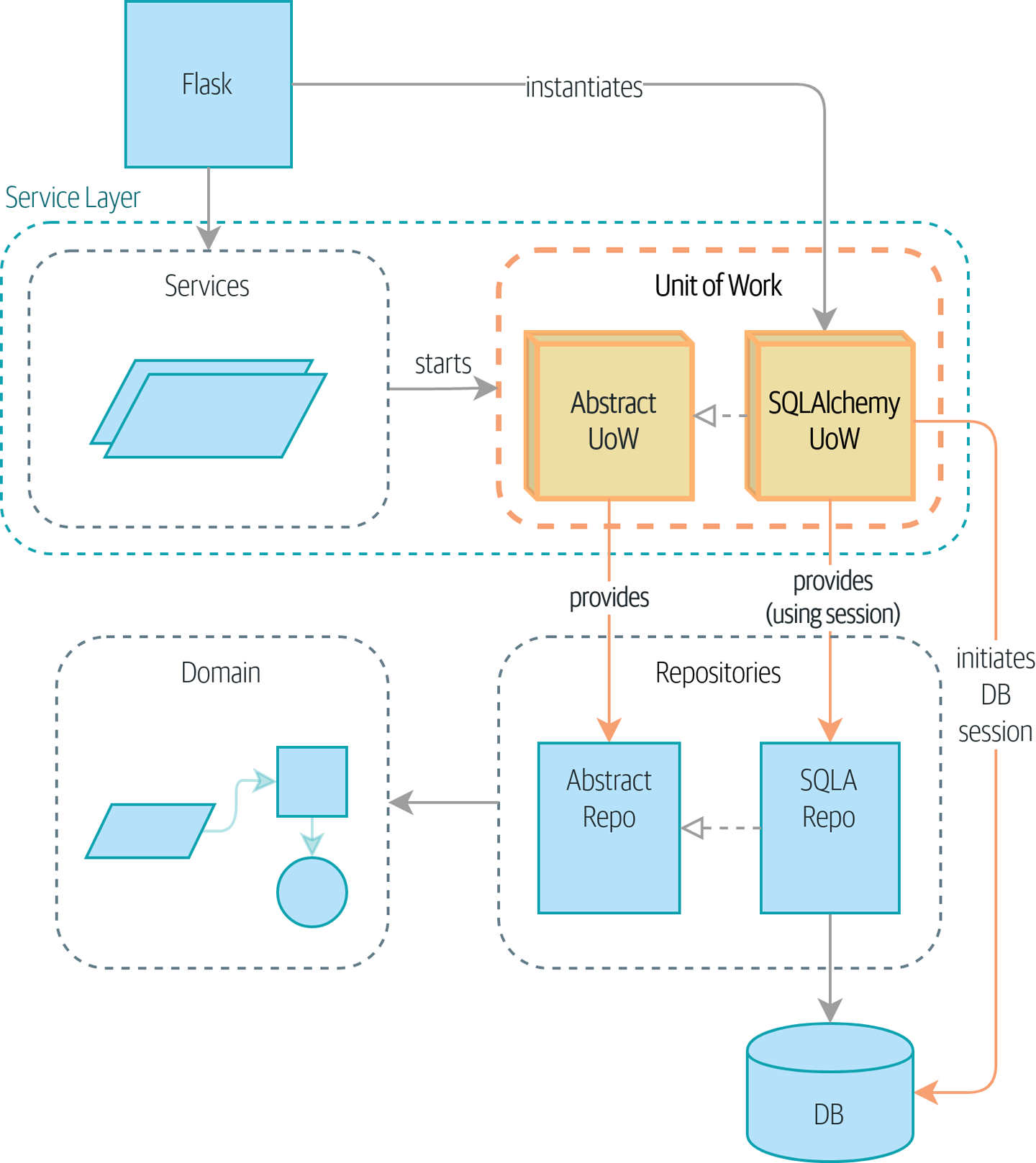
- 이 작업은 파이썬의 컨텍스트 매니저를 이용해서 만들 수 있다.
# src/allocation/service_layer/unit_of_work.py
DEFAULT_SESSION_FACTORY = sessionmaker( #(1)
bind=create_engine(
config.get_postgres_uri(),
)
)
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory #(1)
def __enter__(self):
self.session = self.session_factory() # type: Session #(2)
self.batches = repository.SqlAlchemyRepository(self.session) #(2)
return super().__enter__()
def __exit__(self, *args):
super().__exit__(*args)
self.session.close() #(3)
def commit(self): #(4)
self.session.commit()
def rollback(self): #(4)
self.session.rollback()
- UoW를 사용해서 만든 서비스 계층
# src/allocation/service_layer/services.py)
def add_batch(
ref: str, sku: str, qty: int, eta: Optional[date],
uow: unit_of_work.AbstractUnitOfWork, #(1)
):
with uow:
uow.batches.add(model.Batch(ref, sku, qty, eta))
uow.commit()
def allocate(
orderid: str, sku: str, qty: int,
uow: unit_of_work.AbstractUnitOfWork, #(1)
) -> str:
line = OrderLine(orderid, sku, qty)
with uow:
batches = uow.batches.list()
if not is_valid_sku(line.sku, batches):
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches)
uow.commit()
return batchref
- UoW 패턴은 데이터 무결성 중심의 추상화다.
- 도메인 모델의 일관성을 강화하고 성능을 향상시킬 때 도움이 된다.
- 파이썬의 콘텍스트 매니저는 원자적으로 한 그룹으로 묶어야 하는 코드 블록을 시각적으로 쉽게 볼 수 있게 해준다.
- 트랜잭션 시작과 끝을 명시적으로 제어할 수 있다.
- 트랜잭션 말고도 이벤트, 메시지 버스를 사용할 때도 원자성은 도움이 된다.
- 하지만 ORM이 이미 원자성의 좋은 추상화를 제공할 수도 있다.
Chapter 7 - 애그리게이트와 일관성 경계
- 도메인 객체가 개념적으로나 영속적 저장소 안에서 내부적으로 일관성을 유지하는 방법, 일관성 경계(Consistency boundary)
- 애그리게이트(Aggregate)는 다른 도메인 객체들을 포함하며 이 객체 컬렉션 전체를 한꺼번에 다룰 수 있게 해주는 도메인 객체
- 데이터 변경이라는 목적을 위해 한 단위로 취급할 수 있는 연관된 객체의 묶음 (에릭 에번스, 도메인 주도 설계)
- 애그리게이트에 있는 객체를 변경하는 유일한 방법은 애그리게이트와 그 안의 객체 전체를 불러와서 애그리게이트 자체에 대해 메서드를 호출하는 것
- 모델이 복잡해지고 엔티티와 값 객체가 늘어나면서 서로 참조가 얽히고설킨다. 그래서 누가 어떤 객체를 변경할 수 있는지 추적하기 어려워진다.
- 모델 안에 컬렉션이 있으면 어떤 엔티티를 선정해서 그 엔티티와 관련된 모든 객체를 변경할 수 있는 단일 진입점으로 삼으면 좋다.
- 예를 들면 쇼핑몰의 ‘장바구니’는 한 단위로 다뤄야 하는 상품들로 이루어진 컬렉션이다. 각 장바구니는 자신만의 불변조건을 유지할 책임을 담당하는 동시성 경계다.
마무리